A new blog post about our latest work, explaining and deconstructing The Lottery Ticket Hypothesis, is live!
Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
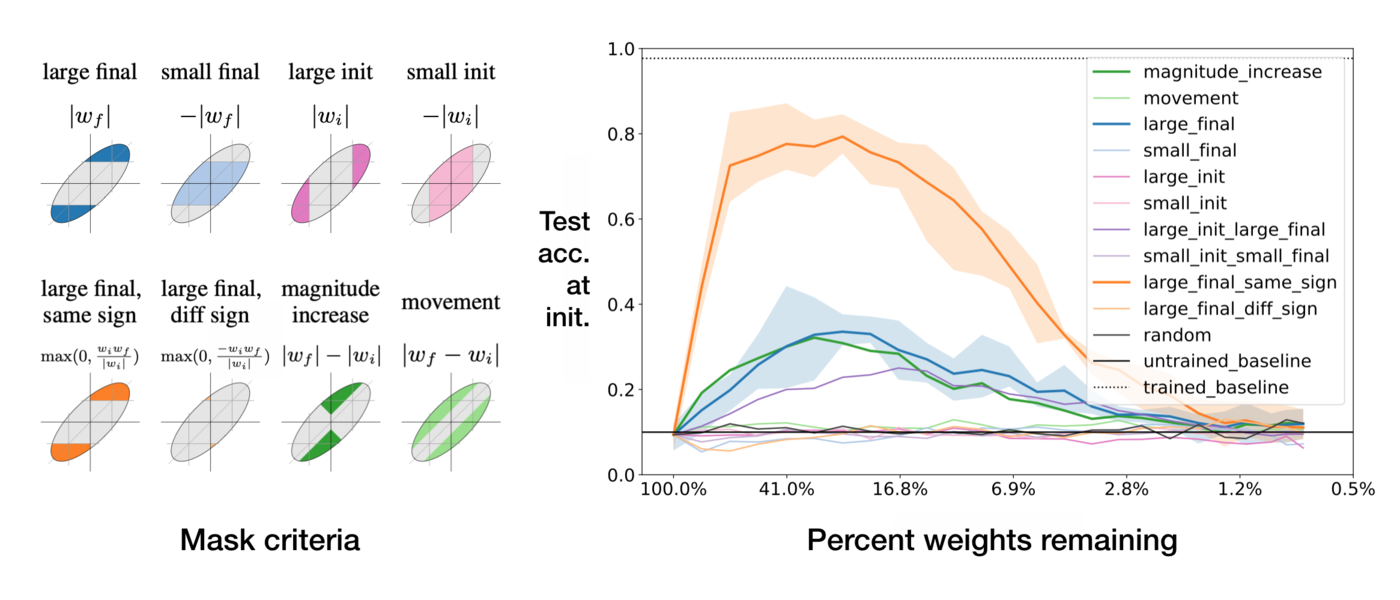
You might already know about the fantastic Lottery Ticket paper, to be presented at ICLR 2019 this week. In it they show that a very simple algorithm of neural network weight pruning—delete small weights and retrain—can find sparse trainable subnetworks, or “lottery tickets”, within larger networks that perform as well as, and at times better than, the full network.
Their results interest us with all that’s left untold. What about Lottery Ticket networks causes them to show better performance? What explains the fact that when you find a working subnetwork and reinitiate it, it no longer works? What is particular about the tightly coupled pruning mask and the initial set of weight? Why does simply selecting large weights constitute an effective criterion for choosing a mask? Would other criteria for creating a mask work, too?
In answering these questions we found more surprising behaviors of neural networks (yes, they never fail surprising you), and offered explanations, including:
- why setting weights to zero is important,
- how signs are all you need to make the re-initialized network train, and
- why masking behaves like training.
We also discover the existence of Supermasks, masks that immediately make an untrained, randomly initialized network better!
Read about all these results in the blog post, and the arxiv paper.